
Recent Keyword Extraction Techniques
Recently I got interested in keyword extraction problem in NLP. For about 2 weeks I read many papers about recent techniques applied in that task and I want to do a short overview of what I found interesting and useful.
Introduction
Keyword extraction is used in information retrieval and data mining. Keyword can be any word or noun phrase from
document that summarizes the main topic. Having such keywords from given text is very helpful for search. These keywords
are reach features extracted from document which can improve results in several nlp tasks such as: document
classification, clustering, recommendations, indexing, searching and summarization. There are many
methods for efficient keyword extraction done so far and I am gonna review them. I will pay more attention on recent methods
EmbedRank and SIFRank since they are improving the previous ones.
Datasets
As for many tasks in NLP we have a list of datasets for evaluating keyword extraction methods. Most popular from these
datasets are Inspec, SemEval2017 and DUC2001. You can find broad list of such datasets here.
These datasets have 3 important details which influences on types of methods that does it well. These are: language,
document domain and document length. Language is very crucial for nlp models, not many libraries support all languages
and not all nlp models have the same performance on all available languages. The second important thing is domain since
words and phrases can have different importance and meaning in different domains. The third one is document length.
This factor has different influence on different keyword extraction methods. To be concrete, if we are using simple
frequency based analysis like TF-IDF it has less effect since the increase of document length doesn’t affect frequencies
but Deep models need to be adapted for long document encoding since they have fixed input length.
Evaluation Tools
I have found 2 main approaches applied in evaluation. One comes from information retrieval and another is just simple
keyword match analysis.
- The first approach is very interesting, since it’s applied in some kind of simulation environment where you have
query text and some predefined keywords in that document which describes general topics mentioned in document.
There are indexed documents in database using such keywords. In order to compare keyword extraction model to
given baseline (human expert) you have to compare ranks of retrieved documents using original keywords to the ones retrieved
using your model’s extracted keywords. Then some advanced statistical measures are applied to calculate similarity between
you model’s search results and original results (results are ranked documents actually). There are many implementations
of such tools. One, very old but widely used is trec_eval which is written
in
cand it’s kind of headache to build and run. It has it’s own data format and you model’s output should be converted into that format in order to do evaluation. The recent one is trectools. It is kind of summary of all such tools ever existed. It’s written in python and gives you better interface to do some analysis using standard data science libraries (NumPy,SciPy,Pandas, andMatplotlib). The code is built usingobject-oriented paradigmwhich enables you to easily extend some methods and add new ones. - The second approach is simple compared to the first one since it just involves just a comparison of extracted keywords to
original ones. You are taking top N keywords extracted by your model and compare to original ones. Then calculate standard
classification scores (
F1,Precision,Recall,map, etc). No specific library or tool is available for it since, it can be written in few lines of code.
Supervised vs Unsupervised
There are plenty of them but I will only consider some of them in more details since they are important. These
algorithms can be divided in 2 class: supervised and unsupervised. Supervised algorithms have better performance since
they are using labeled data. But labeling of such data takes too much human resource which sometimes doesn’t worth at all.
One problem with supervised models is that they can’t generalize well to other domains and it makes them less popular.
Unsupervised models are more robust since they aren’t using any domain specific knowledge. As they are using more
general approaches, they can generalize better in most of the cases.
Supervised Algorithms
All existing supervised models are kind of binary classifiers. Their goal is to classify candidate phrases into positive
or negative classes. These models are using features such as: term-frequencies, position, part-of-speech tags, etc. Some
models are integrating external knowledge from Wikipedia, citations etc. I didn’t find any deep learning model for
supervised keyword extraction. The main reason for this can be the performance and maintenance of deep learning models,
but I amn’t sure and there can be many other reasons for that.
Unsupervised Algorithms
The main traditional unsupervised models are based on statistics or graphs.
- Statistics based algorithms use general statical features like:
word frequency,n-grams,word locations,document grammar, etc. Unfortunately these statistical features aren’t enough to do deep analysis of documents. They can’t explain dynamics such as context change and complex relationships between words. - Graph based ones are representing document as a graph of words and their relations. They are effective in some cases
but their performance can be extended using some external knowledge. According to
review paper of Papagiannopoulou and
Tsoumaka this was summarized as embedding base models. Using pre-trained language models it’s possible to achieve
state-of-the-art in many supervised tasks. Such models are
Elmo,BERT,XLNetand others. They better reflect the feature dynamics in text.
EmbedRank
This model appeared in 2018. It outperformed previously leading graph-based approaches. The main idea of this algorithm
is to represent candidate phrases and the whole document in embedding space and then making assumption that most relevant
keyword embeddings are closer to the document embedding and cosine distance between these 2 vectors is a measure of
relevance. After applying these algorithm we sometimes get aliases since two similar phrases are selected and some
important phrases are missed. That’s happening because the optimization objective is only relevance. If we add one more
objective which is diversity we will do better. Then we should do some trade-off between relevance and diversity which
can be done using Maximal Marginal Relevance (MMR) method. Finally it worked well and actually outperformed all
previously existing models. One important detail here Sent2Vec
is used for document embeddings. (These two papers are published on same year). Here is a simulation of relevant and
diverse phrase selection.

SIFRank
This model appeared in 2020. It improved previous baseline which was EmbedRank. Authors did 3 main contribution from this work:
SIF- sentence embedding model which describes relationship between sentence and topic of document. Then they use Autoregressive pre-trained modelElmocombined withSIFto calculate phrase and document embeddings. The cosine similarity is used to calculate distance between candidate phrase and topic.- New method for large document segmentation to speedup embedding calculations. The idea is to divide document in small
fragments, calculate their embeddings separately (can be done in parallel) and then merge them into one. When document
is divided into different parts there is some information loss, hence overall performance is decreasing. To avoid too
much information loss they defined
embedding-anchorfor each word. Embedding anchor is an average of contextual embeddings of the same word appeared in different places in document. This method rebounds the performance loss caused by document segmentation. Position-biased weightsfor candidate phrases to improve keyword extraction in long documents. Such weights are applied to candidate phrases which gives additional information about phrase relevance. This weight is calculated as inverse of first position where that candidate phrase appeared. This technique is proved to be working. Simply, there is an evidence that important words appear at the beginning of document.
One important thing to note from this approach: in order to have good similarity measure of sentence and document’s topic,
we need to have such a model that encodes that information. There are two different type of pre-trained language models:
Autoregressive (AR) and Autoencoding (AE). Autoregressive models are trying to estimate probability distribution
of text corpus with an autoregressive model. Autoencoding models aren’t doing explicit density estimation. Further, there
is a pretrain-finetuning discrepancy since they are using [MASK] tokens on training time and never use them on
fine-tuning. SIFRank authors tested both types of pre-trained models ARs (Elmo, XLNet) and AEs (BERT-like) and they
found that Elmo was performing best.
I amn’t going into the details here but it’s very interesting to read the actual paper to understand more.
Evaluation Results
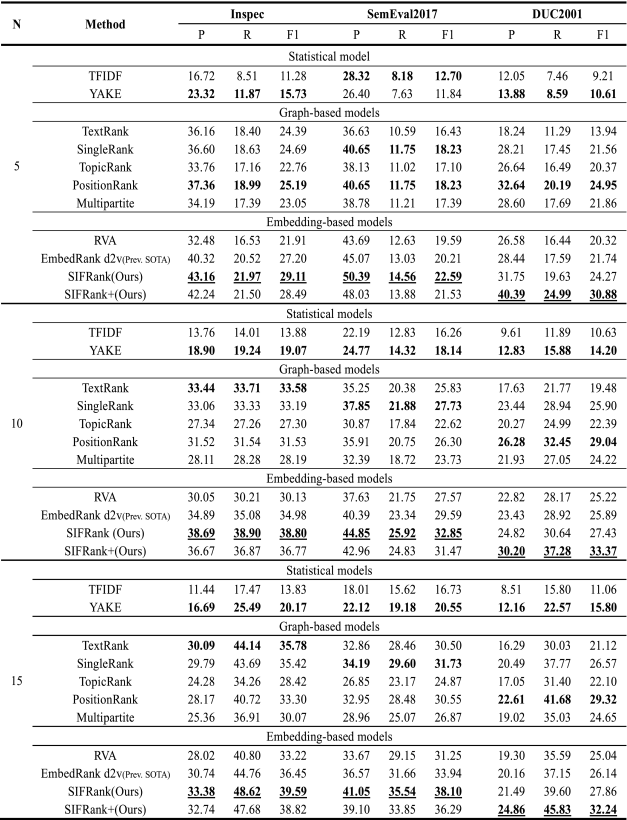
Implementations
You can find original implementations of Embedrank and SIFRank on github.
Simplified Docker versions
I actually got tired until I made them work as needed so I decided to re-implement them using docker-compose and
put all the preparation stuff into Dockerfile which does everything for you. You can find the implementations of both
models on my github. Embedrank is
here and SIFRank is
here. Just clone and enjoy them with little effort. In case
you have any problems running them just create an issue and I will take care of them.
Conclusion
Keyword extraction is very interesting task and can be successfully applied in many business solutions. Most of the available methods are using pre-trained language models. Hence, the external knowledge which is mined in pre-trained models are a good source of many solutions. As pre-trained models improve we will have better solutions for such kind of problems. All we need to do is to perfectly distill the knowledge of huge pre-trained models and apply it to our solutions.
References
https://github.com/sunyilgdx/SIFRank https://ieeexplore.ieee.org/document/8954611 https://github.com/LIAAD/KeywordExtractor-Datasets https://github.com/hanxiao/bert-as-service#q-are-you-suggesting-using-bert-without-fine-tuning https://github.com/epfml/sent2vec https://www.aclweb.org/anthology/N18-1049/ https://github.com/usnistgov/trec_eval https://github.com/joaopalotti/trectools http://ielab.io/publications/pdfs/palotti2019trectools.pdf http://www.www2015.it/documents/proceedings/companion/p13.pdf https://deepai.org/publication/a-review-of-keyphrase-extraction


Leave a comment