
Relevant Phrase Tagging in Semantic Search
Once I was doing one project about semantic similarity search I got an idea of extracting important keywords from search results. I applied one intuitive feature importance technique which worked well. I am gonna share this idea and maybe someone will find it interesting and useful.
Introduction
Semantic search is very interesting problem in nlp. You can actually use pre-trained model embeddings and any distance measure like cosine similarity to create working example of semantic search engine. It’s kind of simple approach and you can find many examples of it. One that I used it bert-as-a-service which is very popular for now. Since transformers are performing well in many nlp tasks they can be used for text embeddings. Several pooling strategies are applied to that model in order to get better embeddings. There is another approach where you fine-tune this model to learn cosine similarity of actual pairs of documents which seems to be working better, but it needs big amount of labeled sentence pairs for your domain which is hard to collect.
Semantic Search System
I took one example from medium where simple semantic search system architecture
is described. Architecture looks something like that:  So here are three main components: Flask API, BERT service and Elasticsearch. There are 3 containers assembled using
docker-compose.
So here are three main components: Flask API, BERT service and Elasticsearch. There are 3 containers assembled using
docker-compose.
- Flask API - takes textual input, calculates embedding and retrieves indexed documents in Elasticsearch which are semantically similar.
- BERT service - takes list of texts and converts into 768 dimensional embedding vectors. If text is longer than hidden size of BERT model (768, 1024, etc) it will trim the right part. It’s recommended to use sentences or paragraphs and not whole document. Whole document can be fragmented and indexed separately for better semantic search results.
- Elasticsearch - holds texts or large document fragments with it’s metadata and it’s embedding vector of type dense_vector which is added in Elasticsearch to extend document ranking possibilities. Actually, you can measure cosine similarity and rank documents using it.
Relevant Phrases
I got an idea to mark important keywords into semantic search results. Since I didn’t have any keyword extraction method for indexed documents I decided to do it automatically. I tried to any Interpretable Machine Learning method for important phrase detection. Since ranking was done using cosine similarity measure some simple assumption could be done to find important phrases. Assumption is something like that: removing important phrases (considering multiple occurrence) from text should decrease cosine similarity more that non-important phrases. In order to achieve the result we need to consider and define several things:
- Candidate Phrases - taking n-grams is kind of overkill and does many complications in that case. It’s better to extract all noun phrases from given text and replace them with neutral word.
- Phrase Replacement - neutral words for replacing such candidate phrases can be “that”, for example. It is kind of general for any noun phrase. Several candidates can be chosen and then randomly sampled the replacement word. Removing that phrase can also work but since we are working contextual sentence embeddings, it seems to be breaking some sentence structure. Removal can work when sentence embedding is an average of its’ work vectors.
- Importance Score - we are taking query text and semantic search results. We are taking each query result, remove or replace candidate phrases separately and recalculate cosine similarity between perturbed and query text. Finally you can subtract cosine cosine similarity of original and replace texts. The cosine similarity difference will show the importance of each candidate phrase. Higher change in cosine similarity means higher importance of word.
Did it work?
Yes it did! It it was giving meaningful results. Unfortunately I didn’t have any labeled dataset for it to measure
results but what was ranked as important it was really important. From what I have seen from results, I can say that
precision was good but I can’t tell anything about recall. Here is one example from query results to take a look.
(That example is actually taken randomly and isn’t the best one) 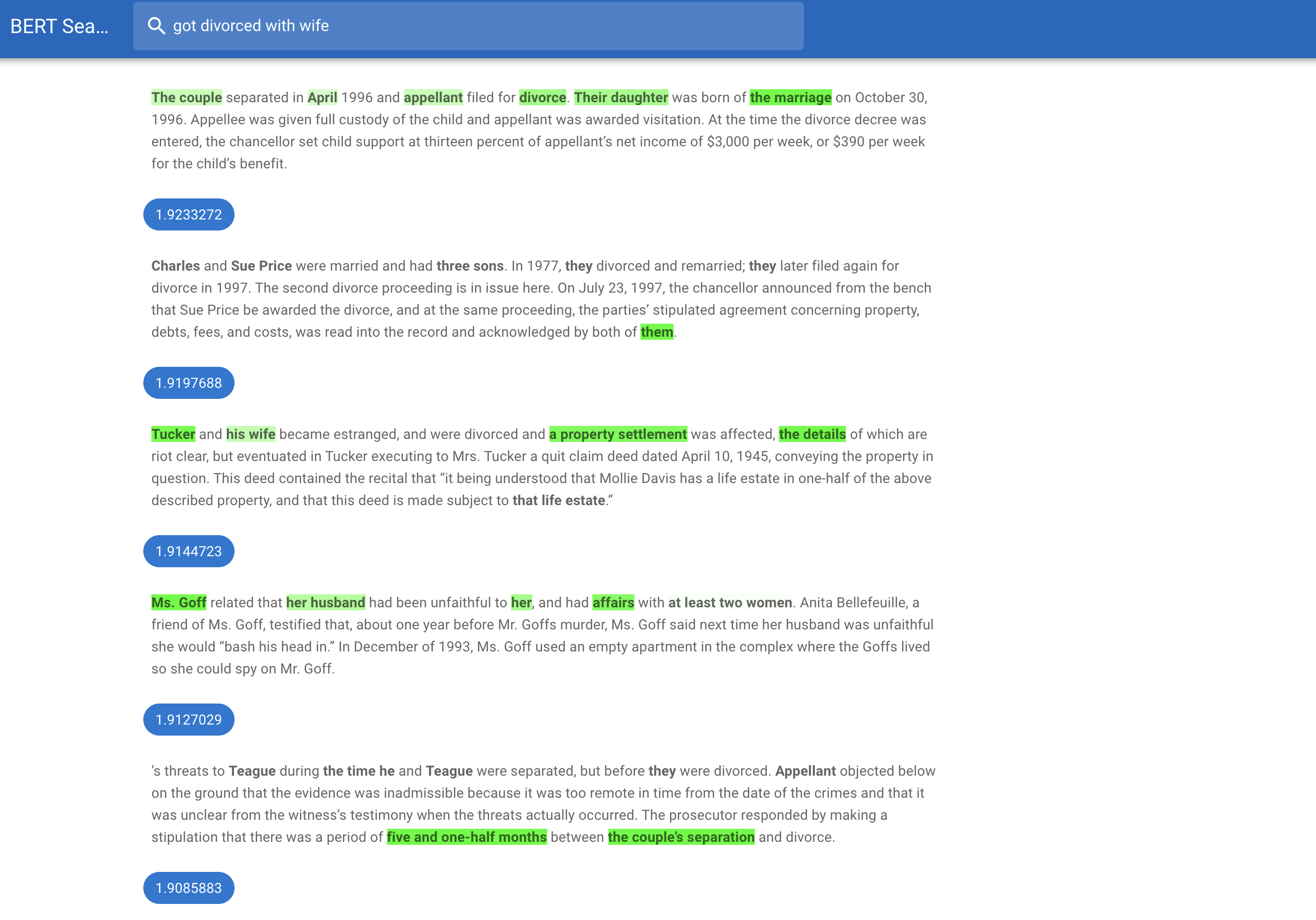 .
.
Feature Importance Implementation
Here is my implementation fo Feature Importance and you can take a closer look. I used spacy library for candidate phrases extraction from text. For embeddings I used bert as a service (which I mentioned above) for text embedding scikit-learn library for cosine similarity calculation.
from typing import Tuple, Iterator, Dict, List
import spacy
from bert_serving.client import BertClient
from sklearn.metrics.pairwise import cosine_similarity
class FeatureImportance:
"""Implementation of Black-Box Feature importance. Finds important features in target text which causes high
high similarity on query text.
Feature: spaCy's document noun_chunks which are actually chunks of nouns that represent important parts of
sentence.
Black-Box: any model which gives good text embeddings optimized for cosine similarity search.
"""
def __init__(self, nlp: spacy.language, bert: BertClient, loss: str = 'l1'):
"""Takes spaCy's language model, bert encoder model and loss parameter"""
self.nlp = nlp
self.bert = bert
self.loss = loss
self.pos_color = "0,255,0"
self.neg_color = "255,0,0"
self.min_alpha = 0.001
def fit(self, query: str, target: str) -> Tuple[str, dict]:
"""Calculates feature importance on target text, then colors important features in text"""
feature_importance = self.feature_importance(query, target)
marked_target = self.mark_important_features(target, feature_importance)
return marked_target, feature_importance
def features(self, text: str) -> Iterator[Tuple[str, int, int]]:
"""Extracts features (noun chunks) from text and returns them with original indices"""
for chunk in self.nlp(text).noun_chunks:
yield (chunk.text, chunk.start_char, chunk.end_char)
@staticmethod
def perturb_feature(text: str, feature: Tuple[str, int, int]) -> str:
"""Removes given feature from text. (can be replaced with synonyms from different domain)"""
return text[:feature[1]] + text[feature[2]:]
def texts_and_features_perturbed(self, text: str) -> Iterator[Tuple[Tuple[str, int, int], str]]:
"""Iterates on target text and perturbs existing features in it (remove or replace)"""
for feature in self.features(text):
yield (feature, self.perturb_feature(text, feature))
def feature_importance(self, query: str, target: str) -> Dict[Tuple[str, int, int], float]:
"""Calculates feature importance values in target text using cosine similarity loss normalization"""
features_and_texts = [
((None, 0, 0), query), # original query text to calculate it's embedding
(('', 0, 0), target) # original target text to calculate it's embedding
]
# collect all extracted features (noun chunks) from text and it's perturbed version (feature removed)
for feature, replaced_target in self.texts_and_features_perturbed(target):
features_and_texts.append((feature, replaced_target))
# calculate embeddings of all texts (including query and target texts) using BertClient in one batch
embeddings = self.bert.encode([text for _, text, in features_and_texts])
# get query and target embeddings
query_emb = embeddings[0]
target_emb = embeddings[1:] # this includes original target text also
# calculate cosine similarities between query embedding and target embeddings (original and perturbed ones)
cosine_similarities = list(cosine_similarity([query_emb], target_emb)[0])
# calculate normalized cosine losses (feature importance)
feature_importance = {}
for (feature, _), norm_loss in zip(features_and_texts[2:],
self.normalize_similarity_losses(cosine_similarities)):
feature_importance[feature] = norm_loss
return feature_importance
def cosine_loss(self, original: str, perturbed: str) -> float:
"""Calculates cosine loss between original and perturbed cosine similarity"""
if self.loss == 'l1':
return self.l1_loss_signed(original, perturbed)
elif self.loss == 'l2':
return self.l2_loss_signed(original, perturbed)
else:
raise ValueError(f"{self.loss} type of loss isn't supported!")
@staticmethod
def l1_loss_signed(original: str, perturbed: str) -> float:
"""L1 loss but saves sign (for negative and positive importance)"""
return original - perturbed
@staticmethod
def l2_loss_signed(original: str, perturbed: str) -> float:
"""L2 loss but saves sign (for negative and positive importance)"""
return (-1) * (perturbed > original) * (original - perturbed) ** 2
def normalize_similarity_losses(self, cosine_similarities: List[float]) -> List[float]:
"""Normalized feature losses will give us some idea about feature importance. It can be negative or positive
in range [-1,1]. -1 means that removal of that feature will increase cosine similarity between query and
target document a lot. 1 means that removing of that feature will decrease the cosine similarity between them,
hence it's very important for document matching and can be considered as good keyword.
Args:
cosine_similarities: cosine similarity between query and target (original and perturbed ones)
Returns:
normalized losses (feature importance)
"""
# get cosine similarity between original query and target
orig_cosine_similarity = cosine_similarities[0]
# collect cosine similarities between query and perturbed targets
cosine_losses = []
for cos_sim in cosine_similarities[1:]:
cosine_losses.append(self.cosine_loss(orig_cosine_similarity, cos_sim))
# get minimum and maximum values of losses (can be negative and positive
max_loss, min_loss = max(cosine_losses), min(cosine_losses)
# loss will have the same sign but normalized in negative and positive ranges separately
normalized_losses = []
for loss in cosine_losses:
if loss > 0:
normalized_losses.append(loss / max_loss)
elif loss < 0:
normalized_losses.append((-1) * (loss / min_loss))
else:
normalized_losses.append(0.0)
return normalized_losses
def mark_color(self, feature: str, alpha: float) -> str:
"""Marks feature's background with it's relative color (red for negative and green for positive) with
alpha (importance value)"""
if self.min_alpha < alpha or alpha < - self.min_alpha:
return f"<b style=\"background-color:rgba(" \
f"{self.pos_color if alpha > 0 else self.neg_color},{alpha})\">" \
f"{feature}</b>"
else:
return feature
def mark_important_features(self, text: str, alphas: Dict[Tuple[str, int, int], float]) -> str:
"""marks features in given text using estimated alpha values (feature importance)"""
marked_text = ''
last_end = 0
for (feature, st_idx, end_idx), alpha in alphas.items():
marked_text += text[last_end:st_idx] + self.mark_color(feature, alpha)
last_end = end_idx
marked_text += text[last_end:]
return marked_text
Here are some usage code fragment. The actual output is into html format which contains marked phrases and background color has normalized phrase importance value to set alpha (background intensity) value.
import spacy
from bert_serving.client import BertClient
from web.feature_importance import FeatureImportance
if __name__ == '__main__':
bc = BertClient(output_fmt='list')
nlp = spacy.load("en_core_web_sm", disable=['ner'])
fi = FeatureImportance(nlp=nlp, bert=bc)
query = "immigration problems"
target = "Reasons for the change include the geographic mobility of the United States population and post-divorce demands.” Baures, 167 N.J. at 105, 770 A.2d at 222. As our society has become more and more mobile, some courts around the country have imposed a presumption against relocation, while others have imposed a presumption in favor of relocation, and still others have simply applied a best-interest analysis. Ann M. Haralambie, Handling Child Custody, Abuse and Adoption Cases § 7.08 (2001); Baures, supra"
target_colored = fi.fit(query, target)
print(target_colored)
You can explore some relevant work to that in my repository
Conclusions
So, I showed how simple interpretability methods can be applied to text in order to get some insights and extract useful features automatically. You can try your own modifications and your own ideas to do similar stuff. Good luck!
Useful Links
https://christophm.github.io/interpretable-ml-book/ https://github.com/slundberg/shap https://eli5.readthedocs.io/en/latest/overview.html https://github.com/Hironsan/bertsearch https://towardsdatascience.com/elasticsearch-meets-bert-building-search-engine-with-elasticsearch-and-bert-9e74bf5b4cf2


Leave a comment