
Unlocking Georgian Language Understanding: The UD Treebank Project at Ilia State University
The field of Natural Language Processing (NLP) has witnessed remarkable advancements over the years, largely fueled by the availability of high-quality linguistic resources such as treebanks. However, there has been a notable absence of a comprehensive treebank for the Georgian language, hindering the development of NLP models and semantic analyzers for this unique language. In this blog, we’ll delve into the Georgian UD Treebank Development project at Ilia State University, shedding light on its significance, key contributors, activities, and current progress.
The Significance of the Georgian UD Treebank:
The Georgian Universal Dependencies (UD) Treebank is a pioneering initiative that aims to create the first-ever semantic analyzer for the Georgian language. Treebanks are invaluable linguistic resources that provide annotated syntactic and semantic information about sentences, making them essential for various NLP tasks. Currently, there is a dearth of such resources for Georgian, making this project all the more crucial.
Benchmarking Deep NLP Models:
The Georgian UD Treebank also serves as a benchmark dataset for evaluating Deep NLP Models in the context of Georgian language understanding. Just as the CoNLL shared tasks and the GLUE benchmark have played pivotal roles in advancing NLP models globally, this treebank can be a catalyst for similar progress in Georgian NLP. It paves the way for the development of language models and tools that can be integrated into popular NLP libraries like spaCy, NLTK, StanfordNLP, and Stanza.
Key Contributors:
The project is a collaborative effort led by Erekle Magradze and receives funding from the SHOTA RUSTAVELI NATIONAL SCIENCE FOUNDATION OF GEORGIA. Irina Lobzhanidze and Svetlana Berikashvili are primarily engaged in data collection and annotations, while my focus is on model training and evaluation.
Project Activities:
The project has actively participated in the TbiLLC 2023: Fourteenth International Tbilisi Symposium on Logic, Language, and Computation, where the team presented the current status and showcased the first version of the model using a small treebank version. Link to the paper abstract.
Current Progress:
As of now, the Georgian UD Treebank project has approximately 150 sentences and 2000 words labeled, constituting a minimal version required for presentation to the UD community. The project utilizes a tool called ‘udpipe’ (version 1.3.1 dev) to train models based on valid .conllu format files.
Here’s a glimpse of what the dataset looks like:
# sent_id = GLC_00126
# text = გარეგანი შეხედულება მნახველს საკმაოდ ასიამოვნებს.
# translit = garegani šexeduleba mnaxvels sakmaod asiamovnebs.
1 გარეგანი გარეგანი ADJ Adj Case=Nom|Number=Sing 2 amod 2:amod Translit=garegani
2 შეხედულება შეხედულება NOUN Noun Animacy=Inan|Case=Nom|Number=Sing 5 nsubj 5:nsubj Translit=šexeduleba
3 მნახველს მნახველი NOUN Noun Animacy=Anim|Case=Dat|Number=Sing 5 obj 5:obj Translit=mnaxvels
4 საკმაოდ საკმაოდ ADV Adv AdvType=Deg 5 advmod 5:advmod Translit=sakmaod
5 ასიამოვნებს ასიამოვნებს VERB Verb Aspect=Imp|Mood=Ind|Number[subj]=Sing|Person[obj]=3|Person[subj]=3|Subcat=Tran|Tense=Fut|Voice=Act 0 root 0:root SpaceAfter=No|Translit=asiamovnebs
6 . . PUNCT F PunctType=Peri 5 punct 5:punct Translit=.
The dataset has been split into training and holdout sets, comprising 136 and 15 samples, respectively.
Model Performance:
The preliminary results of the model are promising and suggests that more data would improve the performance:
| Component | Steps/Iterations | Metrics |
|---|---|---|
| Tokenizer | Epoch 32, logprob: -9.6536e+02, training accuracy: 99.93% | Heldout tokens: 100.00% Precision/100.00% Recall, Sentences: 100.00% Precision/100.00% Recall |
| Tagger | Iteration 20: Accuracy 100.00% | Heldout accuracy: 72.26% Tokens / 83.22% Lemmas / 64.73% UPOS |
| Parser | Iteration 10: Training logprob -2.7755e+03 | Heldout UAS (Unlabeled Attachment Score): 55.82%, Heldout LAS (Labeled Attachment Score): 49.66% |
Shortly About UDPipe Models and Evaluation
UDPipe (Universal Dependencies Pipeline) is a popular open-source tool for training and applying models for various natural language processing (NLP) tasks, including tokenization, part-of-speech tagging, and dependency parsing. When training these models, it’s essential to evaluate their performance using various metrics. Here’s an explanation of the typical evaluation metrics for the tagger, parser, and tokenizer components in UDPipe:
- Tagger Metrics:
-
Accuracy (ACC): Accuracy is a common metric for part-of-speech tagging. It measures the percentage of correctly tagged words in the test data. A higher accuracy indicates better performance.
-
Precision, Recall, and F1-score: These metrics are often used when dealing with multi-class classification problems like POS tagging.
- Precision: The ratio of correctly predicted positive instances (true positives) to the total predicted positive instances (true positives + false positives). It measures the precision of the tagger.
- Recall: The ratio of correctly predicted positive instances (true positives) to the total actual positive instances (true positives + false negatives). It measures how well the tagger identifies the actual positive instances.
- F1-score: The harmonic mean of precision and recall, which balances between precision and recall. It provides a single score that considers both false positives and false negatives.
-
- Parser Metrics:
-
Unlabeled Attachment Score (UAS): UAS measures the percentage of correctly predicted dependency relations in the parsing task. It counts how many words in the dependency tree have been assigned the correct head (parent) word without considering the specific dependency labels.
-
Labeled Attachment Score (LAS): LAS is similar to UAS but also considers the correctness of the dependency labels. It measures the percentage of words that have both the correct head and the correct dependency label.
-
Root Accuracy: It measures the percentage of sentences where the root word (usually the main verb) is correctly identified as the root of the sentence.
-
- Tokenizer Metrics:
-
Token-level Accuracy: This metric assesses how accurately the tokenizer splits text into individual tokens. It measures the percentage of correctly tokenized tokens in the test data.
-
Tokenization Precision, Recall, and F1-score: Similar to part-of-speech tagging, you can also use precision, recall, and F1-score to evaluate tokenization. Precision measures how many tokens were correctly split, recall measures how many of the actual tokens were captured, and F1-score provides a balance between precision and recall.
-
In all cases, a higher score or percentage indicates better performance. These metrics help NLP practitioners and researchers assess the quality of their trained models and make improvements to optimize them for specific tasks or languages. The choice of which metrics to use may depend on the specific goals and requirements of the NLP application.
Ground Truth Annotations Vs Model Predictions
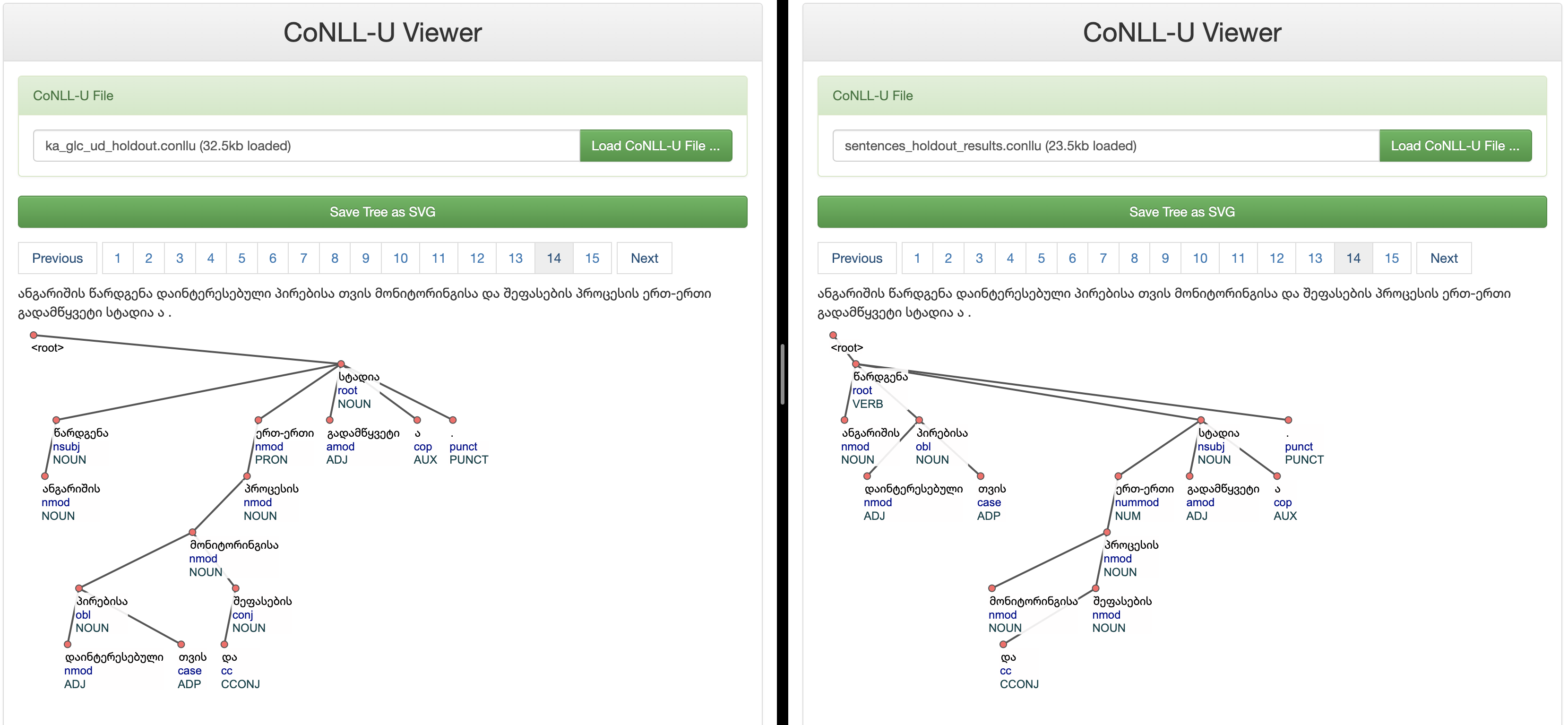
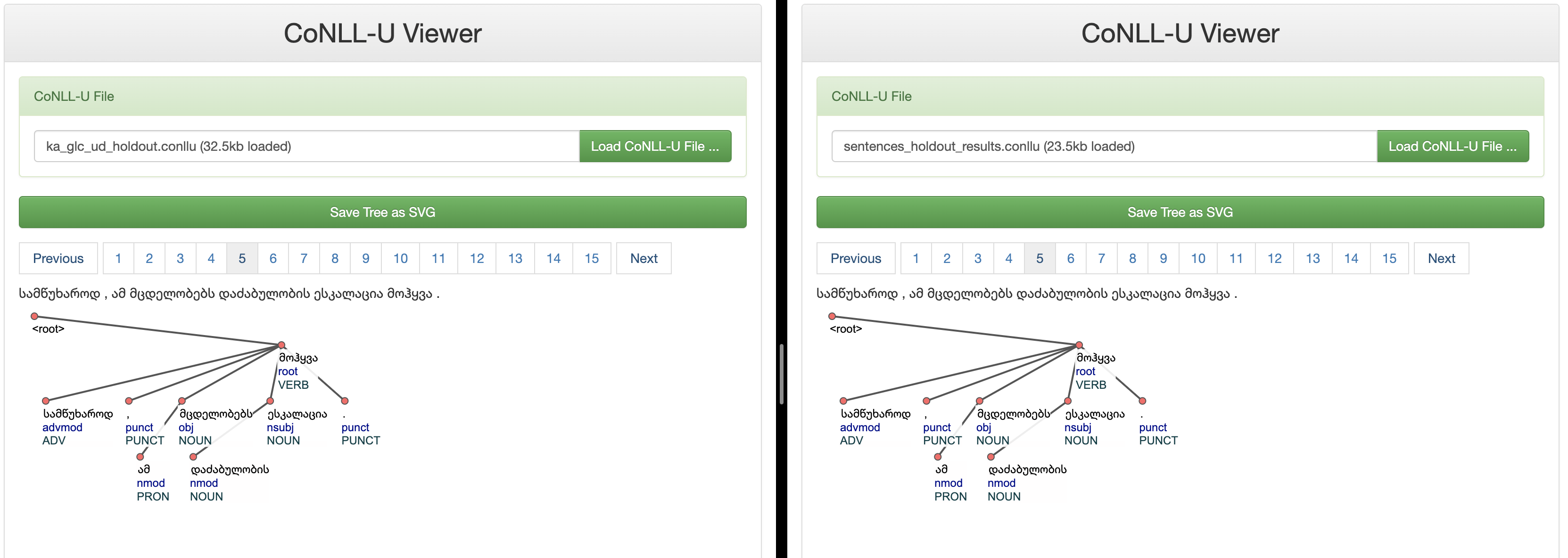
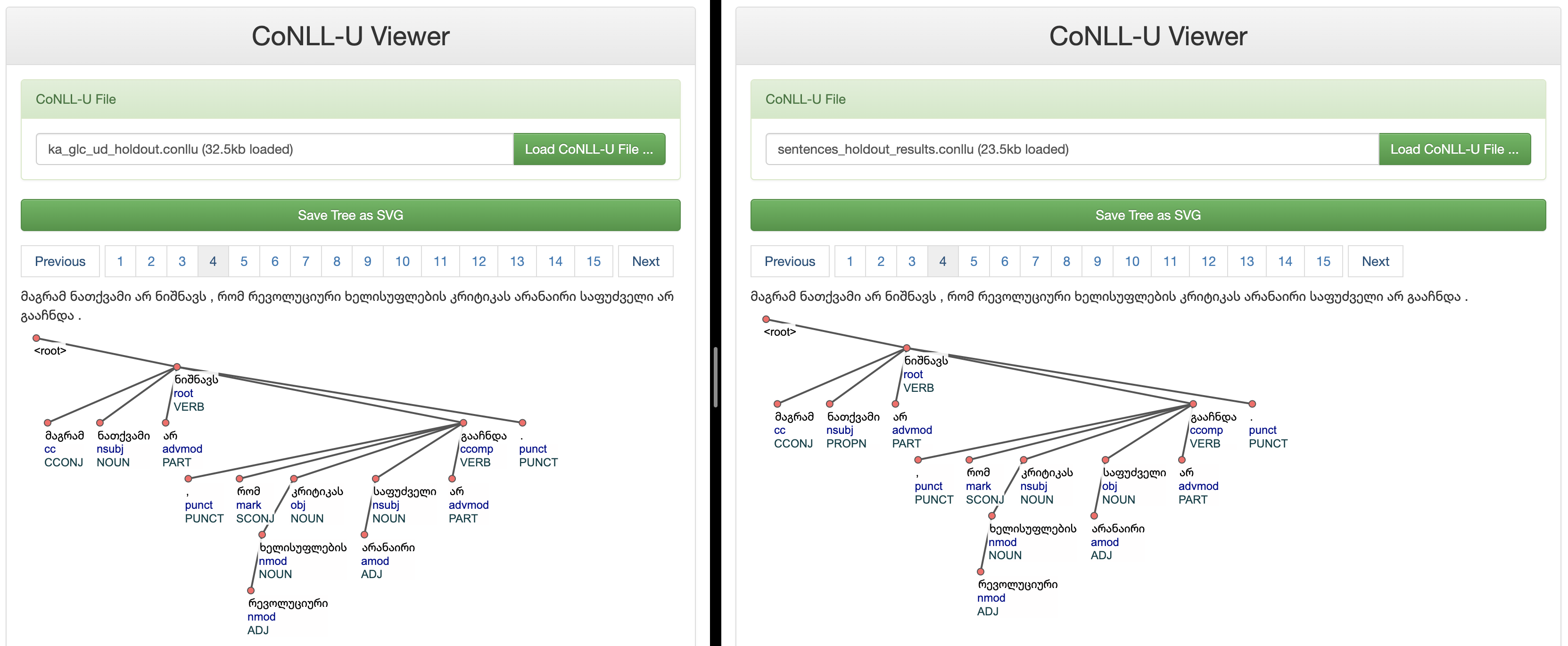
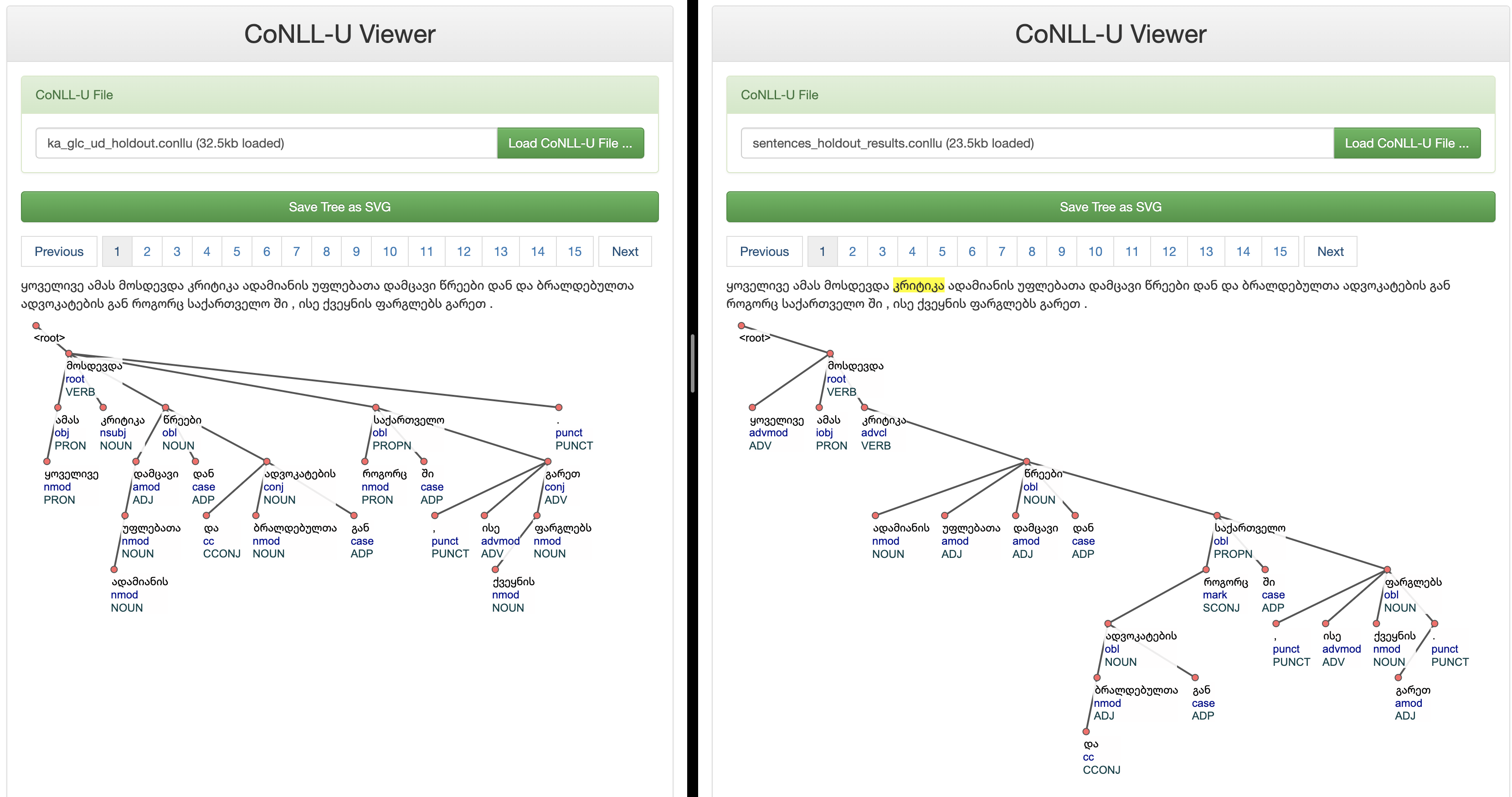
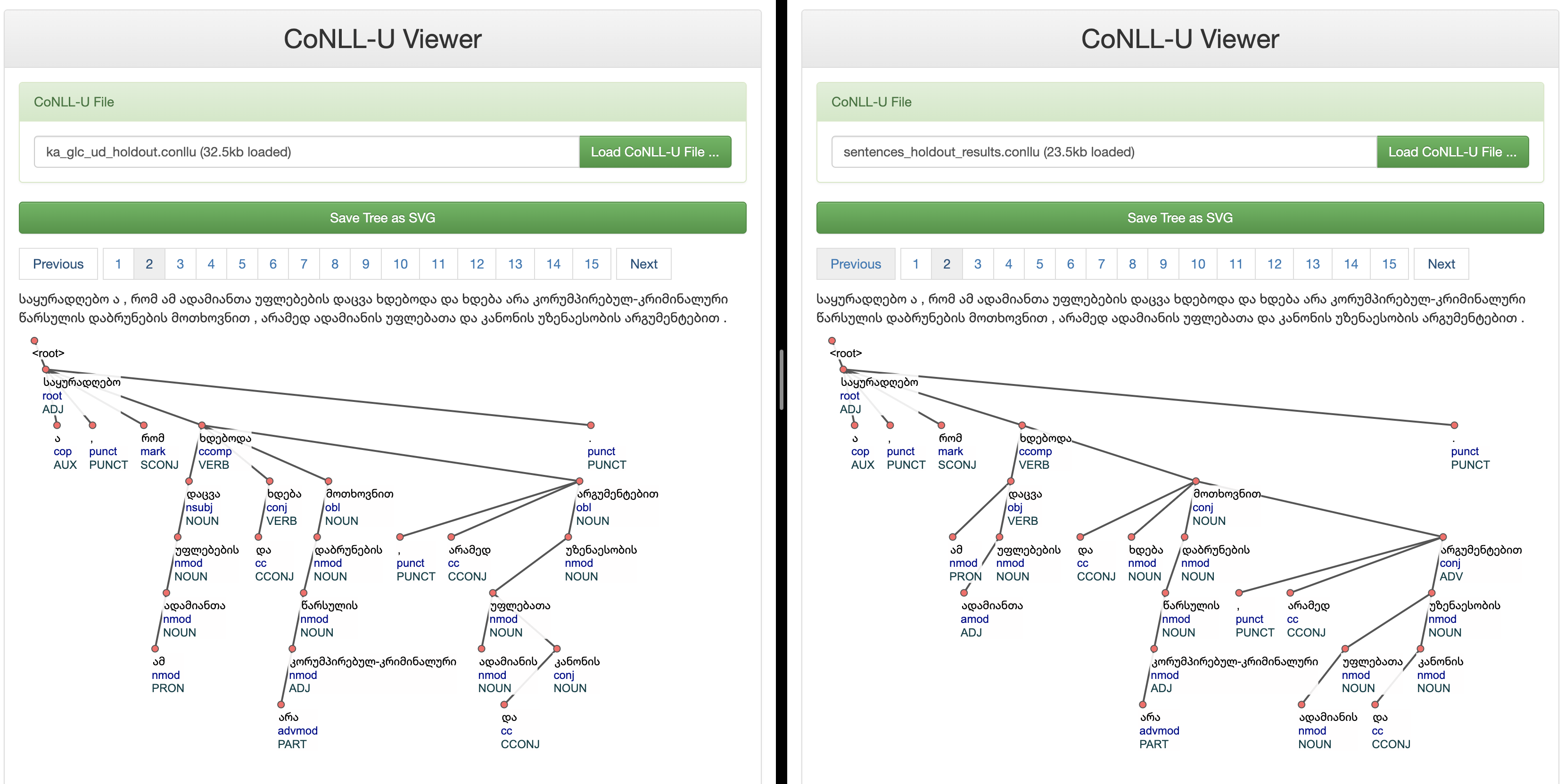
Conclusion:
The Georgian UD Treebank Development project at Ilia State University is a groundbreaking endeavor that holds the potential to transform the landscape of Georgian NLP. With dedicated contributors, promising model results, and the backing of the SHOTA RUSTAVELI NATIONAL SCIENCE FOUNDATION OF GEORGIA, the project is poised to become a cornerstone in advancing linguistic research and NLP tools for the Georgian language. Stay tuned for more updates and exciting developments as this project unfolds its full potential.
Written by ChatGPT It’s based on factual inputs and prompt. I did just small changes to embed images and table.

Leave a comment